

22 Apr How Reinforcement Learning Works
Table of Contents
Introduction
The Reinforcement Learning problem involves a tool that explores an unknown environment to achieve a goal. RL to based on the proposition that all destinations can define by exploiting the expected cumulative reward. The agent must learn to perceive and disrupt the state of the environment using his actions to achieve the maximum bonus. The formal basis for RL borrows from the problem of optimal control of Markov Decision Processes (MDP).
The Main Basics of a Reinforcement Learning are:
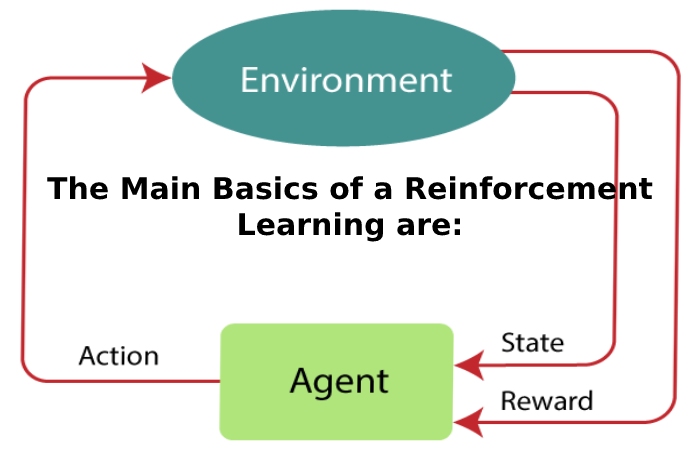
- Agent or learner
- The environment in which the agent interacts
- The agent’s policy to take action
- The reward signal your agent observes when it moves
A proper notion of the reward signal is the value function, which authentically captures the “goodness” of a situation. The reward signal signifies the immediate benefit of being in a particular state. At the same time, the value function captures the cumulative reward expected to collect from that state in the future. An RL algorithm aims to discover the policy of action that maximizes the average value the system can extract from each state.
RL algorithms can broadly categorize as model-free and model-based. Model-free algorithms do not create an explicit model of the environment or MDP. They are closer to trial-and-error processes that run experiments with the environment using actions and directly derive the most appropriate policy. Model-independent algorithms are either value-based or principle-based. Value-based algorithms consider the optimal approach to be a direct result of accurately estimating the value function of each state. The agent networks with the environment to sample courses of conditions and rewards using a recursive relationship defined by the Bellman equation. Given enough studies, the value function of the MDP can estimate. Once the value role is known, discovering the whole policy is simply a matter of greedily acting on the value function in each state of the process. Some popular value-based systems are SARSA and Q-learning. Policy-based algorithms directly predict the optimal policy without modeling the value function.
In Reinforcement Learning
They transform the learning problem into an explicit optimization problem by parameterizing the policy using directly learnable weights. Examples include value-based algorithms, trajectories of intermediary states, and rewards; however, this information to used to improve policy by maximizing the average value function across all states. Popular RL algorithms include the Monte Carlo policy gradient (REINFORCE) and the deterministic policy gradient (DPG). Policy-based approaches suffer from a high variance that manifests as instability in the educational process. Value-based methods, although more stable, are not suitable for modeling continuous action spaces. One of the most potent RL systems, called the actor-criticism algorithm, was created by combining value-based and policy-based approaches. In this algorithm, policy (actor) and value function (critical) to parameterized to ensure efficient use of training data with a stable union.
Model-based RL systems build a model of the setting by sampling situations, taking actions, and observing rewards. The model predicts each condition’s expected reward and the desired future state and possible effort. The first is a regression problem, while the second is a density estimation problem. Given an environment model, the RL agent can plan its actions without directly interacting with the environment. It’s like a thought experiment that a person can run when trying to solve a problem—the learning ability of the RL agent when the planning process to intertwined with the policy forecasting process.
Reinforcement Learning Examples
Any real-world problem where an agent has to interact with an uncertain environment to accomplish a specific goal is a potential Reinforcement Learning application. Here are a few RL success stories:
Robotics. Robots with preprogrammed behavior are helpful in structured environments where the task is repetitive, such as an auto-effort plant group line. However, in the real world, where RL provides a clever way to build general-purpose robots in such scenarios. For example, it has positively applied to robotic path planning, where a robot must discover a short, smooth, and a controllable path between two locations, free of collisions and in harmony with the robot’s dynamics.
Alpha Go. One of the most complex planned games is a 3,000-year-old Chinese board game called Go. Its complexity comes from the fact that there are 10^270 likely board combinations, some instructions of scale more than the game of chess. In 2016, an RL-based Go agent named AlphaGo defeated the most remarkable human Go player. He learned by playing thousands of games with professional players like human players. The latest RL-based Go broker can discover by playing against itself an advantage the human player does not have.
Conclusion
An independent driving system must perform multiple sensing and planning tasks in an uncertain environment. Some specific duties that Reinforcement Learning finds application include vehicle path planning and motion estimation. Vehicle path planning requires several low- and high-level policies to decide on varying temporal and spatial scales. Movement prediction is the task of predicting the movement of pedestrians and other vehicles to understand how the situation may develop depending on the current state of the environment.